vLLM部署大模型
vLLM 是一个用于高效运行和部署大型语言模型(Large Language Models, LLMs)的高性能Python库。也是目前生产环境运行满血大模型参数较为常用的工具。 本文简单介绍如何使用vLLM运行本地下载好的模型参数,
-
安装vLLM
# 创建Python环境 conda create -n vllm python=3.12 -y # 启用环境 source /root/miniconda3/bin/activate conda activate vllm # 安装vllm pip install vllm -
下载模型参数:
https://www.modelscope.cn/models/deepseek-ai/DeepSeek-R1-Distill-Qwen-14Bmodelscope download --model deepseek-ai/DeepSeek-R1-Distill-Qwen-14B --local_dir /root/autodl-tmp/models/DeepSeek-R1-Distill-Qwen-14B -
启动vLLM
# 单卡32G显存不足,需要使用双卡--tensor-parallel-size 2 # 添加--enable-reasoning --reasoning-parser deepseek_r1 使其支持reasoning_content vllm serve /root/autodl-tmp/models/DeepSeek-R1-Distill-Qwen-14B \ --served-model-name DeepSeek-R1-Distill-Qwen-14B \ --enable-reasoning \ --reasoning-parser deepseek_r1 \ --tensor-parallel-size 2 \ --max-model-len 32768 \ --port 6006 \ --host 0.0.0.0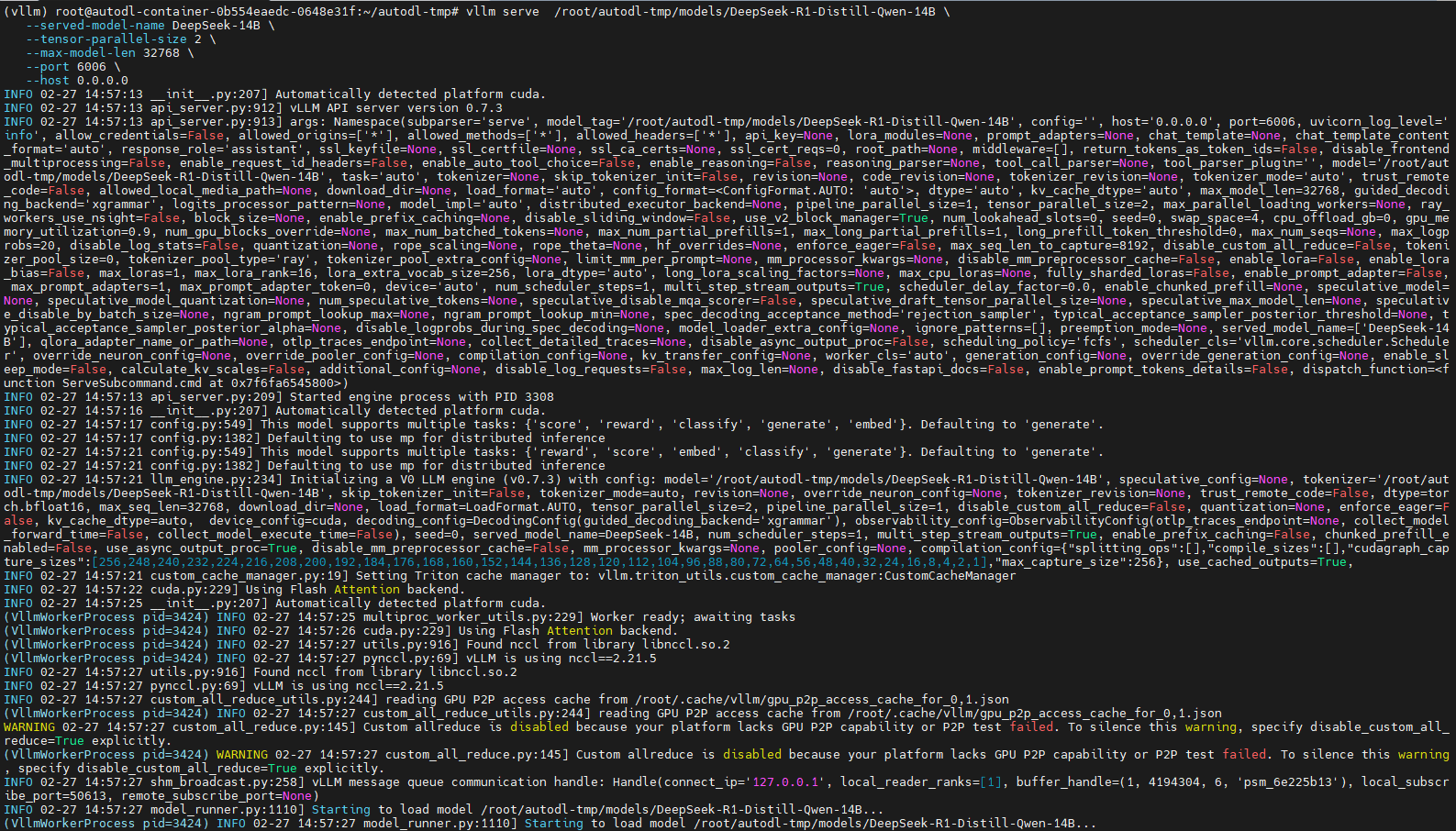
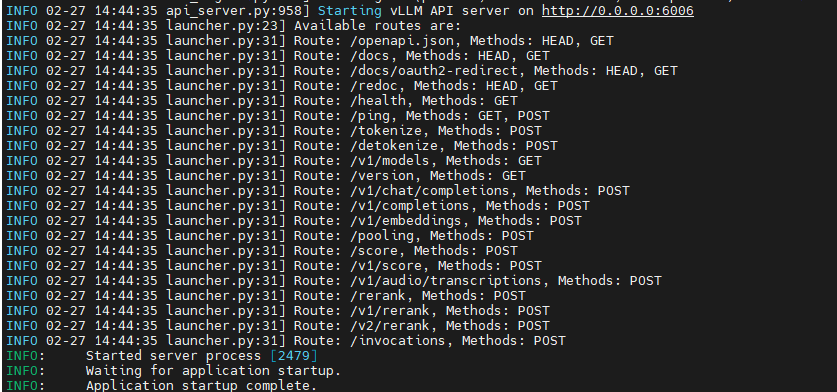
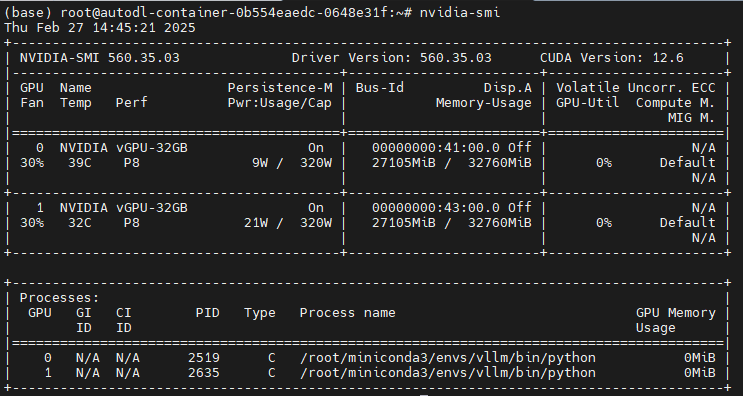
-
测试接口是否正常