Llama.cpp部署大模型
llama.cpp 是一个基于 C/C++ 实现的开源工具,专注于在 CPU 环境下高效部署和推理大型语言模型。其设计目标是降低硬件依赖,通过量化技术和架构优化,让用户无需高性能 GPU 即可运行模型。
本文演示的是使用llama.cpp运行GGUF模型参数的示例,如果你本地GPU显存不足可以通过调整-n-gpu-layers参数来降低对显存的需求。
ModleScope 下载权重文件
下载的权重为unsloth量化的Q4_K_M版本 。
pip install modelscope
modelscope download --model unsloth/DeepSeek-R1-Distill-Qwen-32B-GGUF --include 'DeepSeek-R1-Distill-Qwen-32B-Q4_K_M.gguf' --local_dir /root/autodl-tmp/GGUF

安装llama.cpp
-
下载源码
# 开启autodl代理下载源码 source /etc/network_turbo git clone https://github.com/ggerganov/llama.cpp -
构建源码
# 安装构建依赖 apt-get update apt-get install build-essential cmake curl libcurl4-openssl-dev -y ## -DBUILD_SHARED_LIBS=OFF: 禁用共享库,生成 静态库。 ## -DGGML_CUDA=ON: 启用CUDA支持,以便在有GPU的情况下使用GPU加速。 ## -DLLAMA_CURL=ON: 启用CURL库支持,以便支持网络请求。 cd llama.cpp cmake -B build -DBUILD_SHARED_LIBS=OFF -DGGML_CUDA=ON -DLLAMA_CURL=ON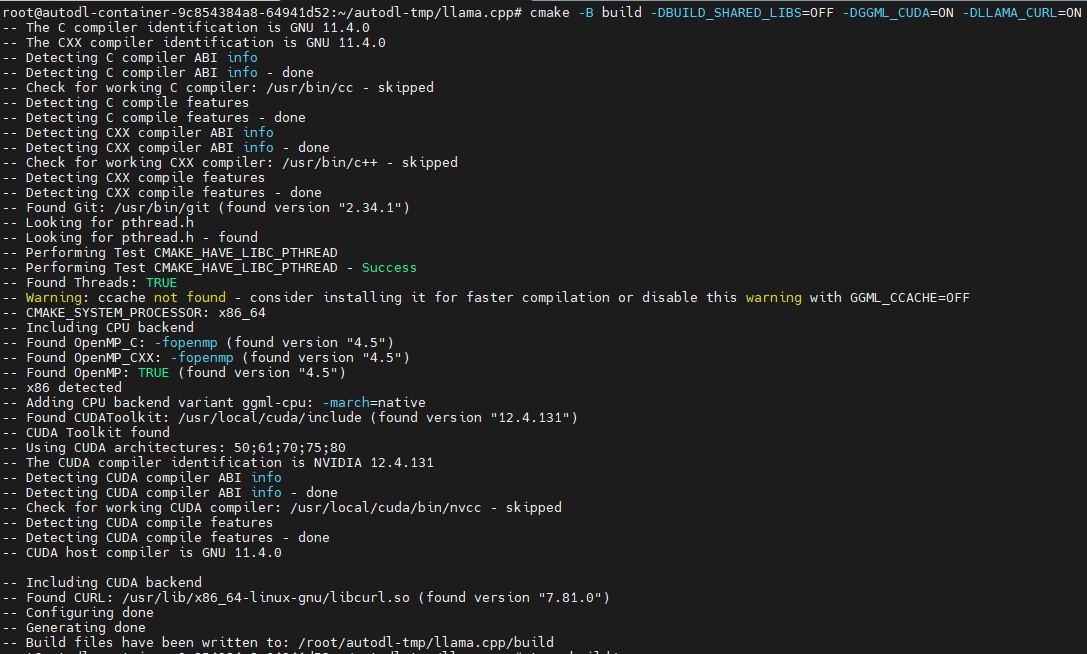
-
构建可执行文件
## -j: 表示并行构建。 ## --clean-first: 表示在构建之前先清理掉之前的构建结果。 cmake --build build --config Release -j --clean-first # --target llama-quantize llama-cli llama-gguf-split llama-server
-
检查编译文件
ll build/bin ,并配置到PATH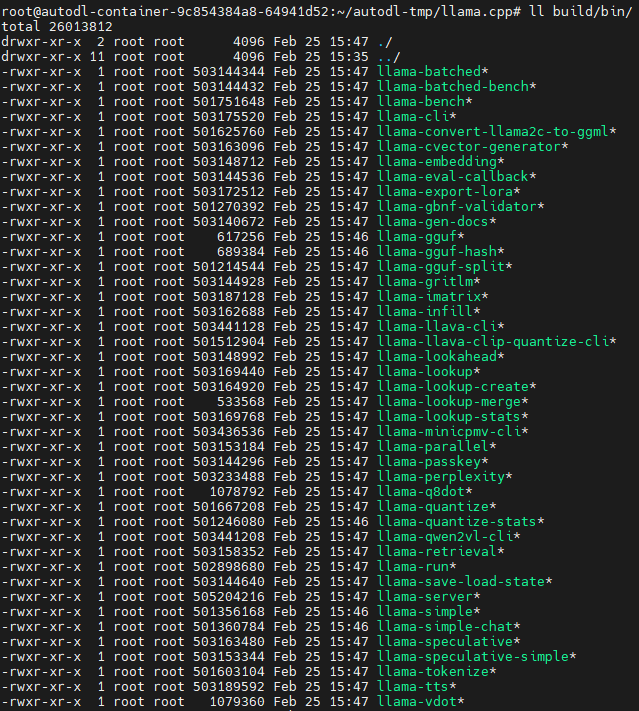
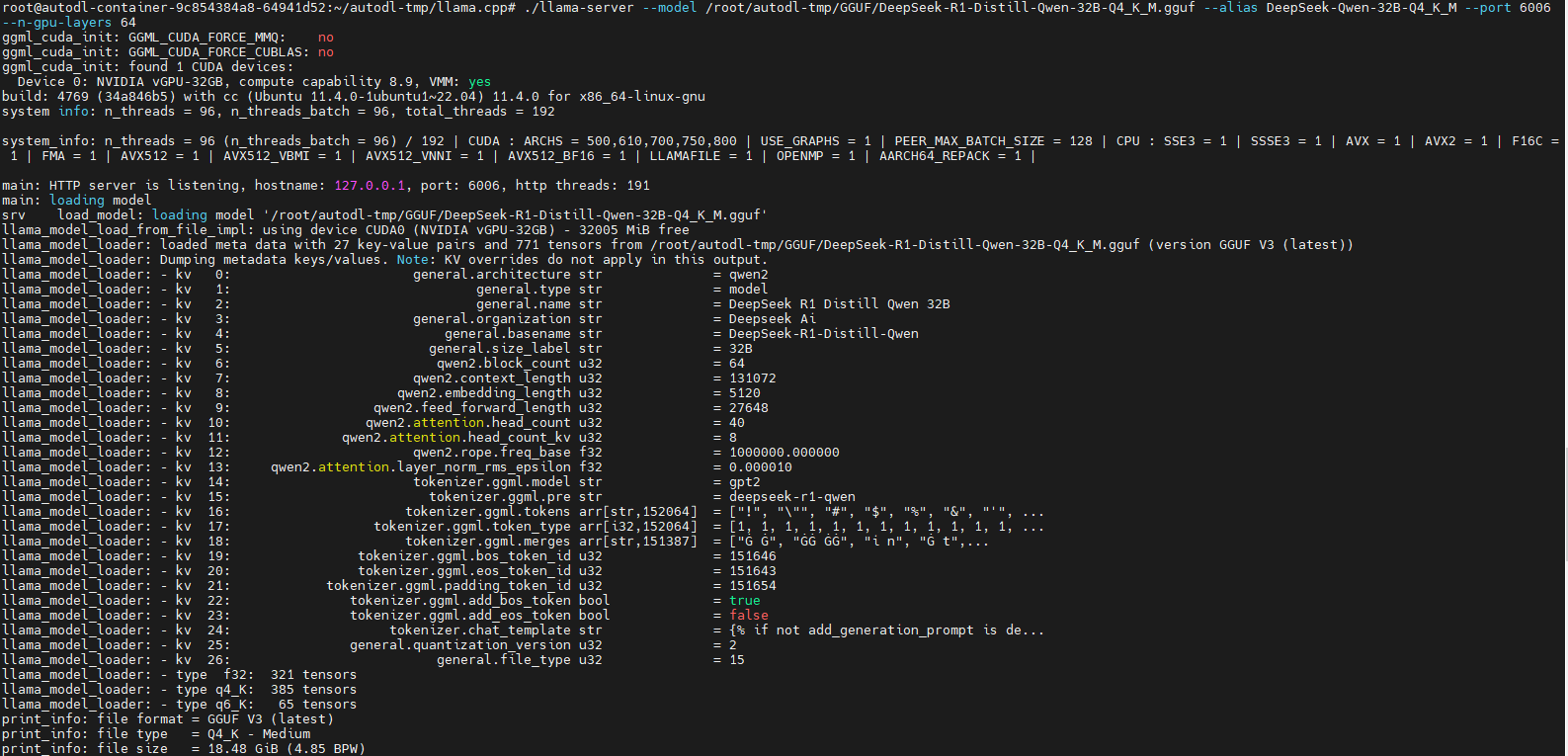
llama-server运行大模型
# 使用全量gpu运行
llama-server --model /root/autodl-tmp/GGUF/DeepSeek-R1-Distill-Qwen-32B-Q4_K_M.gguf --alias DeepSeek-Qwen-32B-Q4_K_M --port 6006 --n-gpu-layers 64
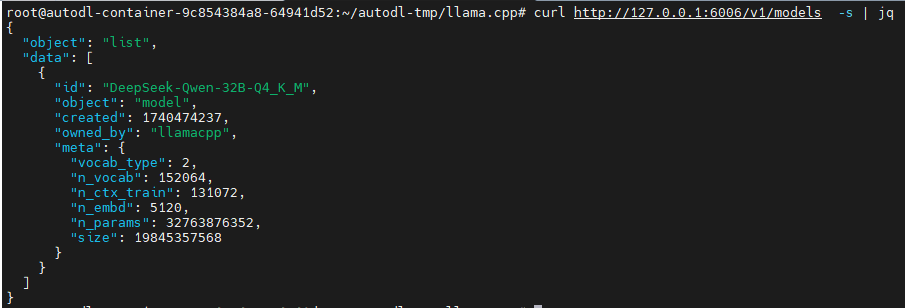
# 测试
curl http://127.0.0.1:6006/v1/models