Llama-Factory微调
Llama-Factory 是一个开源项目,专注于大语言模型进行高效微调(Fine-tuning)。它提供了一套简洁易用的工具和框架,帮助研究者和开发者快速实现大模型在特定任务或垂直领域的适配与优化。本文主要介绍使用medical-o1-reasoning-SFT数据集对Qwen2.5-1.5B-Instruct模型进行LoRa微调的过程。
环境准备
-
准备python环境
conda create -n train python=3.12 conda activate train -
启动jupyter-notebook服务
mkdir -p train cd train pip install jupyter notebook nohup jupyter notebook --allow-root --port 8880 >/dev/null 2>&1 & # 查看运行中的服务以及token jupyter server list
模型和数据准备
-
安装modelscope,并下载要训练/微调的模型参数
pip install modelscope -
下载模型参数
modelscope download --model Qwen/Qwen2.5-1.5B-Instruct --local_dir /root/autodl-tmp/models/Qwen/Qwen2.5-1.5B-Instruc
-
下载数据集
modelscope download --dataset FreedomIntelligence/medical-o1-reasoning-SFT --local_dir /root/autodl-tmp/dataset/FreedomIntelligence/medical-o1-reasoning-SFT
使用Webui进行训练
-
安装Llama-Factory
cd /root/autodl-tmp source /etc/network_turbo git clone --depth 1 https://github.com/hiyouga/LLaMA-Factory.git cd LLaMA-Factory pip install -e ".[torch,metrics]" -
启动
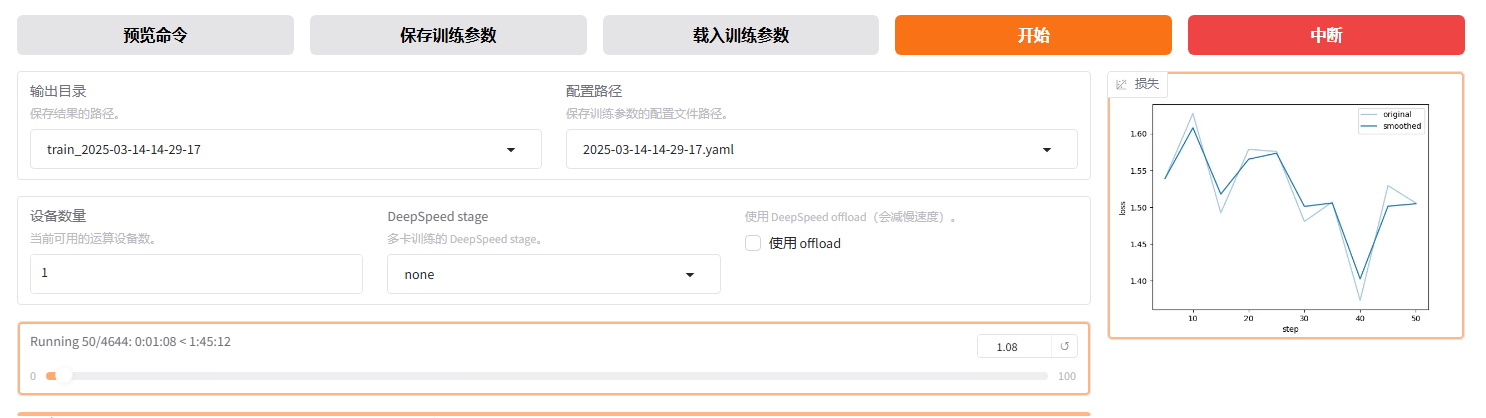
llamafactory-cli webui,监听http://0.0.0.0:7860。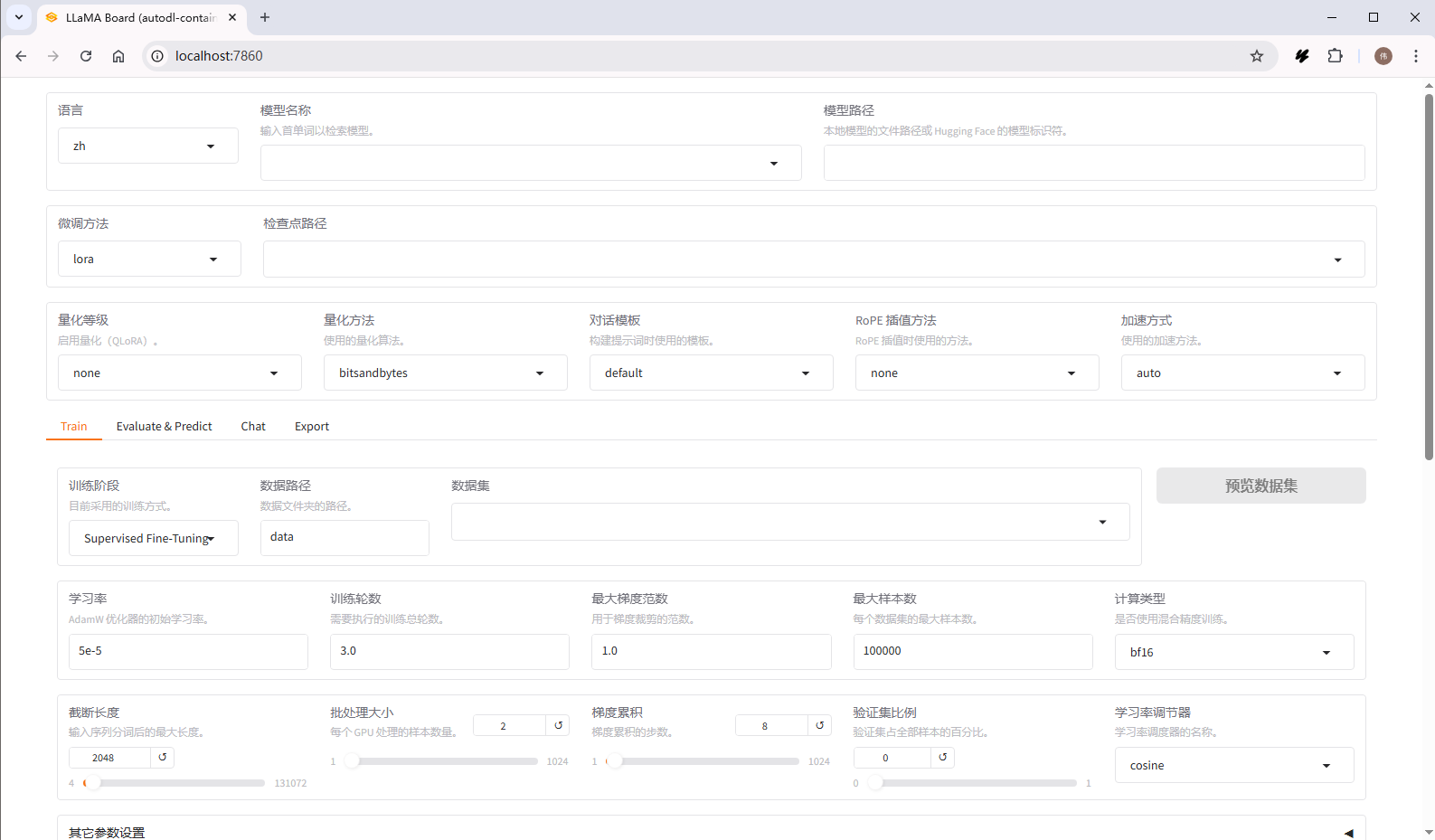
-
添加下载的数据集到Llamafactory,注意做好字段映射。
完整字段映射参照GitHub中的说明:
https://github.com/hiyouga/LLaMA-Factory/blob/main/data/README_zh.md"数据集名称": { "file_name": "该目录下数据集文件夹或文件的名称(若上述参数未指定,则此项必需)", "formatting": "数据集格式(可选,默认:alpaca,可以为 alpaca 或 sharegpt)", "columns(可选)": { "prompt": "数据集代表提示词的表头名称(默认:instruction)", "query": "数据集代表请求的表头名称(默认:input)", "response": "数据集代表回答的表头名称(默认:output)", } }# 修改配置文件 /root/LLaMA-Factory/data/dataset_info.json # 添加自己下载的数据集,数据格式采用默认类型 alpaca "medical_zh": { "file_name": "/root/autodl-tmp/dataset/FreedomIntelligence/medical-o1-reasoning-SFT/medical_o1_sft_Chinese.json", "columns": { "prompt": "Question", "response": "Response" } } -
修改配置对话模板、训练方式、指定模型路径和训练方式
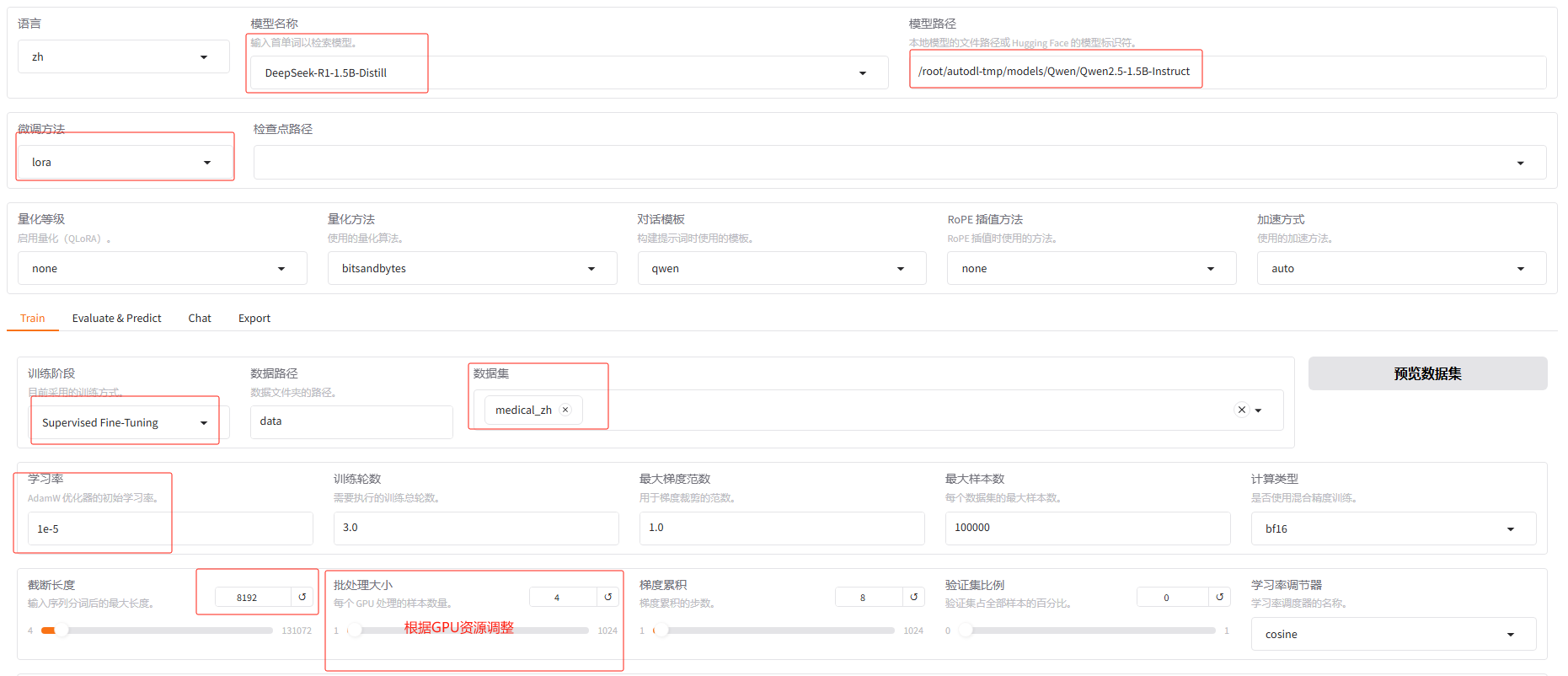
示例训练参数如下:
llamafactory-cli train \ --stage sft \ --do_train True \ --model_name_or_path /root/autodl-tmp/models/Qwen/Qwen2.5-1.5B-Instruct \ --preprocessing_num_workers 16 \ --finetuning_type lora \ --template qwen \ --flash_attn auto \ --dataset_dir data \ --dataset medical_zh \ --cutoff_len 8192 \ --learning_rate 1e-05 \ --num_train_epochs 3.0 \ --max_samples 100000 \ --per_device_train_batch_size 4 \ --gradient_accumulation_steps 8 \ --lr_scheduler_type cosine \ --max_grad_norm 1.0 \ --logging_steps 5 \ --save_steps 100 \ --warmup_steps 0 \ --packing False \ --report_to none \ --output_dir saves/DeepSeek-R1-1.5B-Distill/lora/train_2025-03-14-16-40-33 \ --bf16 True \ --plot_loss True \ --trust_remote_code True \ --ddp_timeout 180000000 \ --include_num_input_tokens_seen True \ --optim adamw_torch \ --lora_rank 8 \ --lora_alpha 16 \ --lora_dropout 0 \ --lora_target all -
开始训练